Tvoříme server¶
Konec teorie, pojďme si vyzkoušet nabyté znalosti v praxi. Začneme tím, že zkusíme vyrobit API. Použijeme k tomu jazyk Python verze 3 a framework Falcon, který se pro API skvěle hodí.
Poznámka
Pokud vám Python není cizí, možná jste už slyšeli o známějších frameworcích Flask nebo Django. V těch by šlo API vytvořit také, ale jsou primárně určeny na tvorbu webových stránek, a to by nám nyní spíš překáželo. Viz také kapitola Frameworky pro tvorbu serveru.
Vytvoříme si pro náš projekt nový adresář cojeapi-server a v něm virtuální prostředí, které si aktivujeme. Poté nainstalujeme Falcon:
(venv)$ pip install falcon
Programujeme aplikaci¶
Začneme tím, že vytvoříme soubor index.py s následujícím obsahem:
import falcon
class PersonalDetailsResource():
def on_get(self, request, response):
response.status = '200 OK'
response.set_header('Content-Type', 'text/plain')
response.body = (
'name: Honza\n'
'surname: Javorek\n'
'socks_size: 42\n'
)
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
V kódu můžeme vidět třídu PersonalDetailsResource s jednou metodou. Třídu jsme si pojmenovali sami podle toho, že je zodpovědná za naše osobní údaje, akorát jsme podle konvence připojili slovo resource.
Název metody on_get() naznačuje, že se stará o HTTP metodu GET. Bere parametry request reprezentující právě přicházející požadavek, a response, tedy odpověď, kterou se chystáme odeslat zpět. Uvnitř metody nastavujeme status kód odpovědi na 200 OK, hlavičku Content-Type na formát těla, a poté tělo na tři řádky řetězců s osobními údaji.
Nakonec do proměnné app ukládáme naši Falcon aplikaci a na dalším řádku jí říkáme, že pokud někdo bude posílat požadavky na adresu /, bude je mít na starost naše třída.
Spouštíme aplikaci na našem počítači¶
Když zkusíme program spustit, zjistíme, že nic nedělá:
(venv)$ python index.py
Poznámka
Jestliže vidíte nějakou chybu, třeba SyntaxError nebo NameError, tak ji opravte. Abyste mohli pokračovat, program se má spustit, nemá nic vypsat, a má se bez chyb hned ukončit.
Falcon se totiž jen tak sám od sebe spustit neumí. Potřebujeme něco, co načte naši aplikaci a bude se chovat jako server. Takových nástrojů je naštěstí hned několik. Pro účely tohoto návodu si vybereme Waitress, protože na rozdíl od jiných funguje i pod Windows. Instalujeme standardně:
(venv)$ pip install waitress
Nyní můžeme spustit naše API. Stačí spustit waitress-serve s nápovědou, kde má hledat aplikaci. Ta je v souboru index.py v proměnné app, takže nápověda pro Waitress bude index:app.
(venv)$ waitress-serve index:app
Serving on http://0.0.0.0:8080
Waitress nám píše, že na adrese http://0.0.0.0:8080 teď najdeme spuštěné naše API. Bude tam čekat na požadavky tak dlouho, dokud v programu nenastane chyba (potom „spadne“), nebo dokud jej v příkazové řádce neukončíme pomocí Ctrl+C.
Poznámka
Používáte-li Windows, uvidíte jinou adresu, která bude obsahovat název vašeho počítače v síti.
Když nyní v prohlížeči půjdeme na adresu http://0.0.0.0:8080, měli bychom vidět očekávanou odpověď:
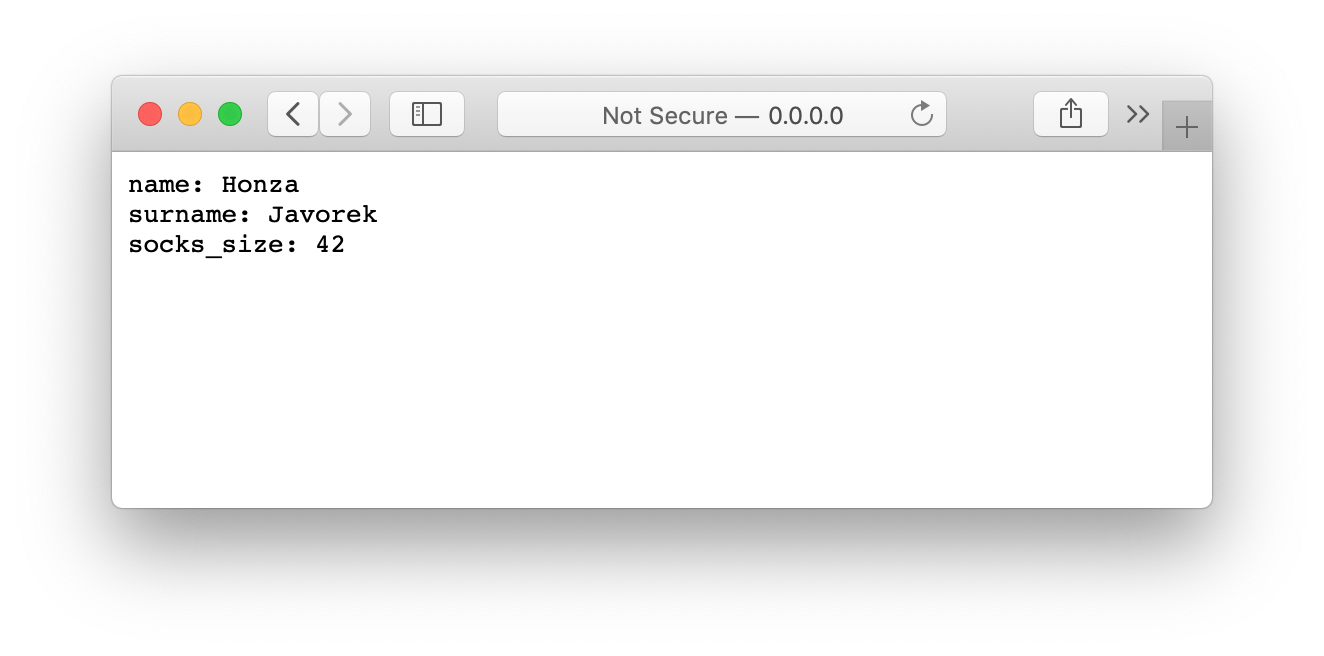
Co když zkusíme curl? Protože nám spuštěné API blokuje aktuální příkazovou řádku, spustíme si další příkazovou řádku v novém okně. Z ní nyní můžeme spustit curl:

Vidíme, že API se chová tak, jak jsme původně chtěli. Odpověď má status kód 200 OK, formát těla odpovědi je v hlavičce Content-Type nastaven na obyčejný text, a v těle zprávy vidíme jméno, příjmení, i velikost ponožek. Kromě toho Falcon s Waitress přidali i nějaké další hlavičky.
$ curl -i "http://0.0.0.0:8080/"
HTTP/1.1 200 OK
Content-Length: 44
Content-Type: text/plain
Date: Sun, 14 Apr 2019 20:37:56 GMT
Server: waitress
name: Honza
surname: Javorek
socks_size: 42
Server nyní můžeme v příkazové řádce ukončit pomocí Ctrl+C a budeme API rozšiřovat o další funkce. Pokaždé, když změníme kód a budeme chtít naše API vyzkoušet, budeme muset Waitress nejdřív restartovat.
Uchováváme data jako slovník¶
Naše data nyní vypadají následovně:
import falcon
class PersonalDetailsResource():
def on_get(self, request, response):
response.status = '200 OK'
response.set_header('Content-Type', 'text/plain')
response.body = (
'name: Honza\n'
'surname: Javorek\n'
'socks_size: 42\n'
)
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
Co si budeme povídat, takto data běžně nevypadají. Většinou jsou někde v databázi, v souboru, apod. Zpravidla je dostaneme jako seznam nebo slovník, ne jako připravený řetězec. Pojďme si tedy tuto situaci nasimulovat. Nejdříve si data vytáhneme do proměnné.
import falcon
personal_details = (
'name: Honza\n'
'surname: Javorek\n'
'socks_size: 42\n'
)
class PersonalDetailsResource():
def on_get(self, request, response):
response.status = '200 OK'
response.set_header('Content-Type', 'text/plain')
response.body = personal_details
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
Nyní z dat uděláme slovník, který až při sestavování odpovědi složíme do textu. Tím rozdělíme uložení dat a jejich prezentaci navenek. Jak už bylo zmíněno, data většinou přicházejí např. z databáze právě jako slovník, takže toto rozdělení je v praxi potřebné a velmi časté.
Změňte data na slovník:
personal_details = {
'name': 'Honza',
'surname': 'Javorek',
'socks_size': '42',
}
Do metody on_get() doplňte kód, který ze slovníku opět složí původní řetězec, tzn. toto:
'name: Honza\nsurname: Javorek\nsocks_size: 42\n'
Tento řetězec pak nastavte jako tělo odpovědi.
import falcon
personal_details = {
'name': 'Honza',
'surname': 'Javorek',
'socks_size': '42',
}
class PersonalDetailsResource():
def on_get(self, request, response):
response.status = '200 OK'
response.set_header('Content-Type', 'text/plain')
body = ''
for key, value in personal_details.items():
body += '{0}: {1}\n'.format(key, value)
response.body = body
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
Takovéto API nám bude fungovat stále stejně, protože ze slovníku opět složí řetězec, který jsme původně posílali v odpovědi. Data jsou nyní ale nezávislá na tom, jak je budeme prezentovat uživateli. Prakticky si tuto výhodu ukážeme v následujících odstavcích.
Posíláme JSON¶
Jak jsme si vysvětlovali, obyčejný text není nejlepší způsob, jak něco udělat strojově čitelné. Zkusíme tedy poslat naše data jako JSON.
import json
import falcon
personal_details = {
'name': 'Honza',
'surname': 'Javorek',
'socks_size': '42',
}
class PersonalDetailsResource():
def on_get(self, request, response):
response.status = '200 OK'
response.set_header('Content-Type', 'application/json')
response.body = json.dumps(personal_details)
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
Jak vidíme, kód se nám s JSONem zjednodušil. Navíc díky tomu, že máme data hezky oddělená od samotného API, nemuseli jsme je nijak měnit. Stačilo změnit způsob, jakým se budou posílat v odpovědi. Když aplikaci spustíme, můžeme opět použít curl nebo prohlížeč a ověřit výsledek.
$ curl -i "http://0.0.0.0:8080/"
HTTP/1.1 200 OK
Content-Length: 59
Content-Type: application/json
Date: Thu, 25 Apr 2019 21:57:39 GMT
Server: waitress
{"name": "Honza", "surname": "Javorek", "socks_size": "42"}
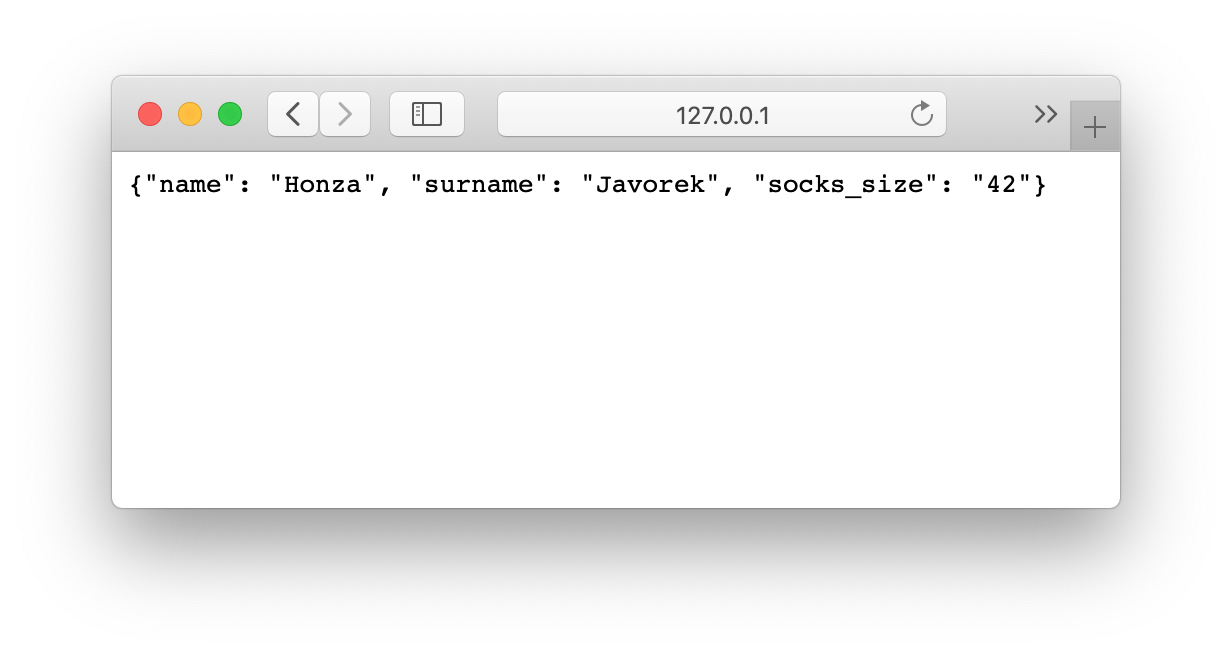
A je to, máme své první JSON API! Už teď jsme se dostali dál, než kam se se svým API dostala ČNB.
Poznámka
Pokud máte v datech diakritiku, bude zakódována. Kdybych se jmenoval Řehoř, vypadal by můj JSON takto: {"name": "\u0158eho\u0159", ...} Jestliže se chceme takového kódování zbavit, můžeme při tvorbě JSONu nastavit ensure_ascii na False. Strojům to bude jedno, ale lidem se to bude lépe číst:
response.body = json.dumps(personal_details, ensure_ascii=False)
Pozor, v příkazové řádce na Windows, která má jiné kódování textu než zbytek světa, uvidíte diakritiku nejspíš stejně rozbitou. To není vada vysílače (vašeho API), ale přijímače (Windows).
Stejně jako je strojům jedno, jestli čtou \u0159 nebo ř, je jim také jedno, jestli jsou, nebo nejsou jednotlivé části JSONu hezky odsazené. Pokud chcete, aby vaše API odsazovalo, nastavte parametr indent na počet mezer (používá se 2 nebo 4):
response.body = json.dumps(personal_details, ensure_ascii=False, indent=2)
Zbytek příkladů nebude tyto možnosti využívat, aby byl kód v ukázkách stručnější.
Protože odpovědi mají ve většině případů status kód 200 a protože JSON je nejpoužívanější formát, tak je Falcon ve skutečnosti nastavuje jako výchozí. Můžeme proto zcela vynechat dva řádky z našeho programu a stále bude fungovat tak, jak jsme chtěli.
Zcela odeberte řádky, kde se nastavuje status kód a hlavička Content-Type. Zkuste, jestli vaše API funguje stále stejně.
import json
import falcon
personal_details = {
'name': 'Honza',
'surname': 'Javorek',
'socks_size': '42',
}
class PersonalDetailsResource():
def on_get(self, request, response):
response.body = json.dumps(personal_details)
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
Přidáváme další endpoint¶
Naše API má zatím pouze jednu adresu, na kterou může klient posílat požadavky. V hantýrce programátorů webů by se řeklo, že má jednu „routu“ (z anglického route). V hantýrce programátorů API by se zase řeklo, že má jeden endpoint. No a API s jedním endpointem není nic moc. Přidáme tedy druhý, který bude světu sdělovat seznam filmů, které bychom chtěli vidět.
import json
import falcon
personal_details = {
'name': 'Honza',
'surname': 'Javorek',
'socks_size': '42',
}
class PersonalDetailsResource():
def on_get(self, request, response):
response.body = json.dumps(personal_details)
movies = [
{'name': 'The Last Boy Scout', 'year': 1991},
{'name': 'Mies vailla menneisyyttä', 'year': 2002},
{'name': 'Sharknado', 'year': 2013},
{'name': 'Mega Shark vs. Giant Octopus', 'year': 2009},
]
class MovieListResource():
def on_get(self, request, response):
response.body = json.dumps(movies)
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
app.add_route('/movies', MovieListResource())
Když aplikaci spustíme, bude na adrese /movies vracet seznam filmů.
$ curl -i "http://0.0.0.0:8080/movies"
HTTP/1.1 200 OK
Content-Length: 196
Content-Type: application/json; charset=UTF-8
Date: Fri, 26 Apr 2019 08:00:53 GMT
Server: waitress
[{"name": "The Last Boy Scout", "year": 1991}, {"name": "Mies vailla menneisyytt\u00e4", "year": 2002}, {"name": "Sharknado", "year": 2013}, {"name": "Mega Shark vs. Giant Octopus", "year": 2009}]
Kdyby každý měl takovéto API, mohl by někdo vytvořit třeba mobilní appku na organizaci filmových večerů. Dávala by dohromady lidi, kteří jsou poblíž a mají stejné filmy na svých seznamech.
Čteme URL parametry¶
Co kdybychom ale chtěli vidět opravdu hodně filmů? Možná bychom chtěli dát uživatelům našeho API možnost výsledky filtrovat. K tomu se nám mohou hodit URL parametry. Chtěli bychom třeba, aby klient mohl udělat požadavek na /movies?name=shark a tím by našel jen ty filmy, které mají v názvu řetězec shark.
Poznámka
Pro stručnost budou následující ukázky kódu znázorňovat už jen úpravy v souboru index.py, ne celý soubor. Pokud by se vám nedařilo ve změnách zorientovat, na konci sekce bude vždy odkaz na celý soubor.
Pojďme se do toho pustit. Začneme tím, že si připravíme funkci, která se bude starat o hledání samotné.
Do souboru index.py přidejte samostatnou funkci filter_movies() s parametry movies a name, která vrátí pouze ty filmy, jejichž název obsahuje hodnotu tohoto parametru, a to bez ohledu na velká a malá písmena. Pokud bude parametr nastaven na None, vrátí všechny filmy.
V následující ukázce je použit cyklus, ale kdo zná funkci filter nebo list comprehentions, může si klidně poradit jinak.
def filter_movies(movies, name):
if name is not None:
filtered_movies = []
for movie in movies:
if name in movie['name'].lower():
filtered_movies.append(movie)
return filtered_movies
else:
return movies
Nyní potřebujeme přečíst z požadavku parametr a použít jej:
class MovieListResource():
def on_get(self, request, response):
name = request.get_param('name')
response.body = json.dumps(filter_movies(movies, name))
Pokud se na náš nový endpoint dotážeme bez parametrů, měl by fungovat stejně jako předtím. Jestliže ale přidáme ?name= do adresy, měla by hodnota parametru filtrovat filmy.
$ curl -i "http://0.0.0.0:8080/movies?name=shark"
HTTP/1.1 200 OK
Content-Length: 93
Content-Type: application/json; charset=UTF-8
Date: Sat, 27 Apr 2019 17:15:11 GMT
Server: waitress
[{"name": "Sharknado", "year": 2013}, {"name": "Mega Shark vs. Giant Octopus", "year": 2009}]
Vidíme, že tentokrát jsme dostali v těle odpovědi jen dva filmy místo čtyř.
Rada
Na kód celého programu se můžete podívat zde: server/07_params/index.py
Detail filmu¶
V našem případě má každý film jen název a rok uvedení, ale většinou data nebývají tak strohá. Pojďme si k filmům přidat víc údajů, ať naše „databáze“ působí o něco víc realisticky.
Když něco evidujeme, zpravidla tomu přiřadíme nějaké evidenční číslo, abychom to mohli jednoznačně odlišit a případně i rychle najít. Programátoři takovému údaji říkají unikátní identifikátor, což zkracují na ID nebo id. Filmy se mohou jmenovat stejně, takže jméno se na to nehodí. Kdybychom měli opravdovou databázi, něco by nám pro každý záznam sama vymyslela, ale takto si musíme poradit sami. Použijeme tedy prostě pořadové číslovky od jedničky.
Kromě id přidáme každému filmu ještě name_cs s českým názvem (cs je mezinárodní standardní kód pro Češtinu), imdb_url s odkazem na IMDb a csfd_url s odkazem na ČSFD.cz.
movies = [
{
'id': 1,
'name': 'The Last Boy Scout',
'name_cs': 'Poslední skaut',
'year': 1991,
'imdb_url': 'https://www.imdb.com/title/tt0102266/',
'csfd_url': 'https://www.csfd.cz/film/8283-posledni-skaut/',
},
{
'id': 2,
'name': 'Mies vailla menneisyyttä',
'name_cs': 'Muž bez minulosti',
'year': 2002,
'imdb_url': 'https://www.imdb.com/title/tt0311519/',
'csfd_url': 'https://www.csfd.cz/film/35366-muz-bez-minulosti/',
},
{
'id': 3,
'name': 'Sharknado',
'name_cs': 'Žralokonádo',
'year': 2013,
'imdb_url': 'https://www.imdb.com/title/tt2724064/',
'csfd_url': 'https://www.csfd.cz/film/343017-zralokonado/',
},
{
'id': 4,
'name': 'Mega Shark vs. Giant Octopus',
'name_cs': 'Megažralok vs. obří chobotnice',
'year': 2009,
'imdb_url': 'https://www.imdb.com/title/tt1350498/',
'csfd_url': 'https://www.csfd.cz/film/258268-megazralok-vs-obri-chobotnice/',
},
]
Když se podíváme, co nyní vrací naše API, uvidíme o dost více dat:
$ curl -i "http://0.0.0.0:8080/movies"
HTTP/1.1 200 OK
Content-Length: 875
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 18:35:00 GMT
Server: waitress
[{"id": 1, "name": "The Last Boy Scout", "name_cs": "Posledn\u00ed skaut", "year": 1991, "imdb_url": "https://www.imdb.com/title/tt0102266/", "csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/"}, {"id": 2, "name": "Mies vailla menneisyytt\u00e4", "name_cs": "Mu\u017e bez minulosti", "year": 2002, "imdb_url": "https://www.imdb.com/title/tt0311519/", "csfd_url": "https://www.csfd.cz/film/35366-muz-bez-minulosti/"}, {"id": 3, "name": "Sharknado", "name_cs": "\u017dralokon\u00e1do", "year": 2013, "imdb_url": "https://www.imdb.com/title/tt2724064/", "csfd_url": "https://www.csfd.cz/film/343017-zralokonado/"}, {"id": 4, "name": "Mega Shark vs. Giant Octopus", "name_cs": "Mega\u017eralok vs. ob\u0159\u00ed chobotnice", "year": 2009, "imdb_url": "https://www.imdb.com/title/tt1350498/", "csfd_url": "https://www.csfd.cz/film/258268-megazralok-vs-obri-chobotnice/"}]
Pokud bychom přidali ještě více údajů a měli v seznamu větší množství filmů, byla by odpověď na endpointu /movies už možná příliš velká a pro některé uživatele našeho API by tam mohlo být možná až příliš mnoho zbytečných informací. Kdybychom tvořili webové stránky, seznam filmů by nejspíš obsahoval jen základní údaje a zbytek by byl na nějaké stránce s detailem filmu pro ty, které to zajímá. Při tvorbě API je praxe stejná.
Pojďme tedy upravit API tak, aby v seznamu vypisovalo jen name a odkaz na detail filmu. Nejdříve ale vytvoříme ten, ať máme na co odkazovat. Jako obvykle se zamyslíme nad tím, jak by měl nový endpoint fungovat:
$ curl -i "http://api.example.com/movies/1"
HTTP/1.1 200 OK
Content-Type: application/json
{
"id": 1,
"name": "The Last Boy Scout",
"name_cs": "Poslední skaut",
"year": 1991,
"imdb_url": "https://www.imdb.com/title/tt0102266/",
"csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/"
}
Chceme tedy, abychom mohli na adrese /movies/1 zjistit informace o filmu s ID číslo jedna, na adrese /movies/2 o filmu s ID číslo dvě, atd. Začneme funkcí, která prohledá seznam a když v něm najde film s daným identifikátorem, vrátí tento film.
Do souboru index.py přidejte samostatnou funkci get_movie_by_id() s parametry movies a id. Funkce prohledá seznam a když v něm najde film s daným identifikátorem, vrátí tento film.
def get_movie_by_id(movies, id):
for movie in movies:
if movie['id'] == id:
return movie
Nyní přidáme další endpoint. To sice už umíme, ale teď je v tom drobný háček. Potřebujeme totiž obsloužit hned čtyři adresy:
/movies/1/movies/2/movies/3/movies/4
Určitě se nám ale nechce přidávat každou zvlášť. Co kdybychom v seznamu měli dvacet filmů? Potřebujeme něco, co by obsloužilo všechny zmíněné adresy.
Falcon nám dává řešení v podobě možnosti zapsat adresu jako „šablonu“, podle které bude odchytávat odlišné adresy a směřovat na jeden a ten samý kód pro jejich obsluhu.
class MovieDetailResource():
def on_get(self, request, response, id):
response.body = json.dumps(get_movie_by_id(movies, id))
app = falcon.API()
app.add_route('/', PersonalDetailsResource())
app.add_route('/movies', MovieListResource())
app.add_route('/movies/{id:int}', MovieDetailResource())
Jak vidíme, pokud zadáme adresu jako /movies/{id:int}, dostane naše metoda on_get() navíc čtvrtý parametr. V něm bude to, co Falcon v adrese odchytne na místě naší značky {id:int}. První část značky i parametr metody si vhodně pojmenujeme jako id. Druhá část značky Falcon upozorňuje na to, že namísto značky očekáváme pouze celá čísla (int odkazuje na vestavěnou funkci int() a anglické slovo integer).
Když nyní spustíme naše API a vyzkoušíme, co vrací na adrese /movies/1, měli bychom dostat informace o prvním filmu v seznamu:
$ curl -i "http://0.0.0.0:8080/movies/1"
HTTP/1.1 200 OK
Content-Length: 201
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 19:20:45 GMT
Server: waitress
{"id": 1, "name": "The Last Boy Scout", "name_cs": "Posledn\u00ed skaut", "year": 1991, "imdb_url": "https://www.imdb.com/title/tt0102266/", "csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/"}
Zkuste udělat požadavky i na všechny ostatní filmy.
Rada
Na kód celého programu se můžete podívat zde: server/09_movie/index.py
Nenalezeno¶
Naše API umí hezky odpovídat v případě, že se číslem trefíme do existujícího filmu. Co se ale stane pokud se dotážeme na nějakou hloupost?
$ curl -i "http://0.0.0.0:8080/movies/hello"
HTTP/1.1 404 Not Found
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 21:48:49 GMT
Server: waitress
Jistě, Falcon díky {id:int} obsluhuje jen adresy s čísly, takže se za nás postará o odpověď. Vrací 404 Not Found, čímž dává uživateli najevo, že se asi spletl, protože na této adrese nic není. Co když se ale dotážeme s číslem, akorát na neexistující film, např. na /movies/42?
$ curl -i "http://0.0.0.0:8080/movies/42"
HTTP/1.1 200 OK
Content-Length: 4
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 19:39:11 GMT
Server: waitress
null
Tady nám Falcon už nepomůže. Adresu obslouží naše metoda a ta, jak vidíme, nevrací zrovna nejlepší odpověď. Žádný film číslo 42 neexistuje, ale naše API se chová, jako by to nebyl žádný problém.
Upravte třídu MovieDetailResource tak, aby s touto situací počítala. Pokud funkce get_movie_by_id() nic nenajde, odpovíme s chybovým status kódem. Tělo posílat žádné nemusíme.
class MovieDetailResource():
def on_get(self, request, response, id):
movie = get_movie_by_id(movies, id)
if movie is None:
response.status = '404 Not Found'
else:
response.body = json.dumps(movie)
Pokud se po této změně dotážeme na neexistující film, měli bychom dostat chybu:
$ curl -i "http://0.0.0.0:8080/movies/42"
HTTP/1.1 404 Not Found
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 20:31:40 GMT
Server: waitress
Získávání informací o existujícím filmu by mělo fungovat stejně jako předtím.
$ curl -i "http://0.0.0.0:8080/movies/1"
HTTP/1.1 200 OK
Content-Length: 201
Content-Type: application/json; charset=UTF-8
Date: Sun, 28 Apr 2019 19:20:45 GMT
Server: waitress
{"id": 1, "name": "The Last Boy Scout", "name_cs": "Posledn\u00ed skaut", "year": 1991, "imdb_url": "https://www.imdb.com/title/tt0102266/", "csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/"}
Rada
Na kód celého programu se můžete podívat zde: server/10_not_found/index.py
V tomto návodu s chybou neposíláme žádné tělo, ale je běžné nějaké poslat a poskytnout v něm uživateli našeho API více informací o tom, co se stalo, např. takto:
$ curl -i "http://api.example.com/movies/42"
HTTP/1.1 404 Not Found
Content-Type: application/json; charset=UTF-8
{"message": "Movie '42' doesn't exist"}
Zatímco status kód 404 Not Found je záležitost standardu protokolu HTTP, strukturu těla chybové zprávy jsme si v tomto případě vymysleli. Aby uživatel našeho API věděl, že se má při chybě podívat na její důvod právě do message, nesmíme to potom zapomenout popsat v dokumentaci.
Poznámka
Na strukturu těla chybové zprávy také existují standardy, byť je málokdo dodržuje:
V případě toho druhého bychom pak v hlavičce Content-Type místo application/json poslali application/problem+json a příjemce by díky tomu hned mohl tušit, jakou přesně strukturu bude tělo chybové odpovědi mít.
Reprezentace filmu¶
Detail filmu máme připravený, takže se můžeme pustit do úprav seznamu filmů, tedy třídy MovieListResource. Jak již bylo zmíněno, budeme v seznamu chtít jen name a odkaz na detail filmu.
Doteď bylo to, co jsme poslali v odpovědi, vždy shodné s tím, jak máme data uložena interně v naší aplikaci. Nyní ale nastává situace, kdy chceme v odpovědi poslat něco trochu jiného, než jak data vypadají ve skutečnosti. Chceme poslat jen určitou reprezentaci těchto dat. Začneme tedy funkcí, která vezme seznam filmů a poskytne nám jeho reprezentaci tak, jak jsme si ji vymysleli:
def represent_movies(movies, base_url):
movies_list = []
for movie in movies:
movies_list.append({
'name': movie['name'],
'url': '{0}/movies/{1}'.format(base_url, movie['id']),
})
return json.dumps(movies_list)
Nyní pojďme upravit MovieListResource. Víme, že adresa našeho API je teď http://0.0.0.0:8080, ale jakmile budeme chtít aplikaci uveřejnit někam na internet, bude zase jiná. Proto je lepší si ji vytáhnout z objektu request. Falcon nám ji poskytuje jako request.prefix.
class MovieListResource():
def on_get(self, request, response):
name = request.get_param('name')
base_url = request.prefix
filtered_movies = filter_movies(movies, name)
response.body = represent_movies(filtered_movies, base_url)
Zbytek úprav by měl být celkem srozumitelný. Nejdříve filmy filtrujeme podle parametrů, poté vytvoříme JSON reprezentaci výsledného seznamu a tu pošleme jako tělo odpovědi. Když aplikaci spustíme a vyzkoušíme požadavkem např. na /movies?name=shark, měla by nám vracet správně filtrovaný seznam filmů v nové podobě:
$ curl -i "http://0.0.0.0:8080/movies?name=shark"
HTTP/1.1 200 OK
Content-Length: 143
Content-Type: application/json; charset=UTF-8
Date: Tue, 30 Apr 2019 19:20:16 GMT
Server: waitress
[{"name": "Sharknado", "url": "http://0.0.0.0:8080/movies/3"}, {"name": "Mega Shark vs. Giant Octopus", "url": "http://0.0.0.0:8080/movies/4"}]
Reprezentace a resource¶
V hantýrce API návrhářů a vývojářů bychom řekli, že film, nebo v tomto případě seznam filmů, je nějaký resource, který zpřístupňujeme uživatelům našeho API na adrese /movies. Je reprezentován jako JSON, v němž má každý film název a odkaz k dalším podrobnostem. Proto má MovieListResource v názvu slovo resource.
Je důležité rozlišit, že resource je pomyslný, nehmatatelný model světa, zatímco reprezentace už je jeho konkrétní zobrazení. Jak jsme si vyzkoušeli u PersonalDetailsResource, lze mít více různých reprezentací pro tutéž pomyslnou věc - čistě textovou, nebo jako JSON, nebo úplně jinou:
$ curl -i "http://0.0.0.0:8080/"
HTTP/1.1 200 OK
Content-Length: 44
Content-Type: text/plain
Date: Sun, 14 Apr 2019 20:37:56 GMT
Server: waitress
name: Honza
surname: Javorek
socks_size: 42
$ curl -i "http://0.0.0.0:8080/"
HTTP/1.1 200 OK
Content-Length: 59
Content-Type: application/json
Date: Thu, 25 Apr 2019 21:57:39 GMT
Server: waitress
{"name": "Honza", "surname": "Javorek", "socks_size": "42"}
Odkazování mezi reprezentacemi¶
Když už jsme u toho našeho prvního endpointu, z jeho odpovědi s osobními informacemi nelze nijak zjistit, že v API zpřístupňujeme ještě i seznam filmů, které chceme vidět. Pojďme to napravit a přidat na seznam filmů odkaz:
class PersonalDetailsResource():
def on_get(self, request, response):
movies_watchlist_url = '{0}/movies'.format(request.prefix)
personal_details_repr = dict(personal_details)
personal_details_repr['movies_watchlist_url'] = movies_watchlist_url
response.body = json.dumps(personal_details_repr)
Voláme dict(personal_details), abychom dostali kopii původního slovníku, kterou můžeme upravovat, aniž bychom ovlivnili obsah proměnné personal_details. Odkaz jsme pojmenovali movies_watchlist_url, protože kdyby to bylo pouze movies_url, nebylo by úplně zřejmé, o jaký přesně seznam filmů se jedná. Samozřejmě i tak by to mělo být popsáno v dokumentaci, ale proč neusnadnit druhé straně práci a nenazvat věci zřejmějším jménem?
$ curl -i "http://0.0.0.0:8080/"
HTTP/1.1 200 OK
Content-Length: 113
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 11:21:02 GMT
Server: waitress
{"name": "Honza", "surname": "Javorek", "socks_size": "42", "movies_watchlist_url": "http://0.0.0.0:8080/movies"}
Pokud bychom odkaz nepřidali, uživatel našeho API, který by dostal pouze jeho výchozí adresu, např. http://api.example.com, by neměl bez dokumentace jak zjistit, že nějaký seznam filmů existuje. Je to jako kdybyste měli web, např. https://denikn.cz, který sice má stránku https://denikn.cz/kontakt/, ale nevede na ni žádný odkaz. Denník N by ovšem uveřejnil návod, kde by bylo napsáno, že pokud do prohlížeče napíšete https://denikn.cz/kontakt/, najdete tam kontaktní informace. Ač to zní absurdně, takto se bohužel spousta skutečných API chová.
Reprezentace vrácené z takových API sice občas propojené jsou, ale pomocí ID, ne pomocí URL. V takovém případě si musíte všechny odkazy tvořit na straně klienta podle dokumentace, místo abyste je dostali od serveru. Pokud server něco změní, vašeho klienta to rozbije. To jde zcela proti tomu, jak byla REST API zamýšlena.
I do našeho malého API bychom ve skutečnosti mohli přidat ještě spoustu dalších odkazů. Podívejte se například na ukázku z GitHub API, kde odkazy plně využívají.
Odkazy na sebe sama¶
Pokud v API používáte odkazy, je dobrým zvykem v odpovědích posílat i odkazy na sebe sama. Každá jednotlivá odpověď by mohla mít url, aby i po stažení klientem v sobě nesla informaci o tom, co byla její původní adresa. Navíc je takové url unikátní, takže by šlo navenek identifikovat filmy jím místo nějakých z kontextu vytržených čísel:
$ curl -i "http://api.example.com/movies/1"
HTTP/1.1 200 OK
Content-Type: application/json
{
"url": "http://api.example.com/movies/1",
"name": "The Last Boy Scout",
"name_cs": "Poslední skaut",
"year": 1991,
"imdb_url": "https://www.imdb.com/title/tt0102266/",
"csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/"
}
Ostatně, v seznamu filmů na /movies už to tak děláme pro každou položku zvlášť. Pojďme upravit detail filmu, aby se choval podobně:
class MovieDetailResource():
def on_get(self, request, response, id):
movie = get_movie_by_id(movies, id)
if movie is None:
response.status = '404 Not Found'
else:
base_url = request.prefix
movie_repr = dict(movie)
movie_repr['url'] = '{0}/movies/{1}'.format(base_url, movie['id'])
del movie_repr['id']
response.body = json.dumps(movie_repr)
Nyní v reprezentaci už není id, nahradilo jej url:
$ curl -i "http://0.0.0.0:8080/movies/1"
HTTP/1.1 200 OK
Content-Length: 231
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 12:40:00 GMT
Server: waitress
{"name": "The Last Boy Scout", "name_cs": "Posledn\u00ed skaut", "year": 1991, "imdb_url": "https://www.imdb.com/title/tt0102266/", "csfd_url": "https://www.csfd.cz/film/8283-posledni-skaut/", "url": "http://0.0.0.0:8080/movies/1"}
Kvůli způsobu, jakým jsme naprogramovali tvoření reprezentace se url oproti původnímu návrhu objevuje sice až na konci naší JSON odpovědi, ale na pořadí položek většinou nezáleží, takže si s tím nebudeme lámat hlavu.
Odkazy na sebe sama bychom mohli přidat i do zbytku reprezentací v našem API a přidat bychom také mohli další odkazy, např. odkaz zpět z detailu filmu na seznam filmů, ale takové úpravy už nejspíš zvládnete samostatně. Pojďme se naučit zase něco nového.
Rada
Na kód celého programu se můžete podívat zde: server/11_repr/index.py
Přidáváme filmy¶
Nyní máme API, které je pouze ke čtení. Řekněme, že bychom chtěli, aby nám někdo mohl doporučit film na zhlédnutí tím, že jej přidá do našeho seznamu. Opět si nejdříve navrhněme, jak by věc mohla fungovat:
$ curl -i "http://api.example.com/movies" --request POST --header "Content-Type: application/json" --data '{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/"}'
HTTP/1.1 200 OK
Content-Type: application/json
Jak vidíme, jde trochu do tuhého. Předáváme několik parametrů, postupně pro jednotlivé části HTTP požadavku. Metodu měníme z výchozího GET, které se psát nemuselo, na POST. Přidáváme hlavičku Content-Type pro tělo požadavku a pak samotné tělo.
A co tedy chceme aby se stalo? Pokud metodou POST přijde požadavek na adresu /movies, náš kód přečte zaslané tělo požadavku (očekává JSON), které reprezentuje film, a přidá tento film do našeho seznamu. Poté odpoví kódem 200 OK. Příchozí data o filmu by měla mít všechny položky, které zaznamenáváme. Nebudeme ale chtít, aby měla id, protože to novým záznamům přiřazuje naše „databáze“ (ani url, protože to vytváří naše API na základě id).
Obsluhujeme POST¶
Možná si domyslíte, že když budeme chtít na adrese /movies obsluhovat POST, bude potřeba do třídy MovieListResource přidat metodu on_post():
class MovieListResource():
def on_get(self, request, response):
...
def on_post(self, request, response):
...
Z požadavku ovšem potřebujeme nějak dostat příchozí tělo a udělat z něj nový film. Jak na to? Falcon nám v tomto ohledu nabízí request.bounded_stream. Je to věc, ze níž můžeme číst tak, jako kdyby to byl soubor. To znamená, že má metodu .read(), kterou lze zavolat, a ona vrátí řetězec s obsahem:
request_body = request.bounded_stream.read()
movie = json.loads(request_body)
Nebo tuto věc můžeme přímo předat jako parametr do json.load(), protože na rozdíl od json.loads(), která očekává řetězec, tato funkce očekává cokoliv, na čem může zavolat .read():
movie = json.load(request.bounded_stream)
S těmito znalostmi by už neměl být velký problém nový film přečíst a přidat do globální proměnné movies, kterou používáme jako „databázi“.
Poznámka
Možná si říkáte, že je to nějaké zbytečně složité. Proč nemůžeme tělo zprávy prostě přečíst rovnou jako řetězec pomocí request.body? Je to proto, že nikdy nevíme, kolik dat nám někdo do API pošle. Kdybychom obdrželi gigabyty dat a Falcon se je snažil rovnou přečíst a uložit do request.body jako řetězec, nejspíš by na takovém množství zmodral a začal se dusit. Co je horší, naše aplikace by s tím nemohla vůbec nic dělat. Takto Falcon nechává na nás, co s tělem zprávy uděláme. Můžeme tělo číst postupně řádek po řádku, aby se API nezadusilo, nebo celé najednou. Falcon nám přes request.bounded_stream dává na výběr, co uděláme. My sice v tomto návodu tělo načteme celé najednou, protože zde gigabyty neřešíme, ale stejně je milé, že na nás Falcon takto myslí.
Jediný zbývající zádrhel je snad v id, které filmu musíme přiřadit. Jak bylo několikrát zmíněno, běžně by jej za nás vymyslela databáze. Žádnou databázi nemáme, takže si vypomůžeme trikem - podíváme se, jaké je nejvyšší ID mezi našimi filmy a tomu novému přiřadíme o jedna větší. Ostatně, reálná databáze by většinou udělala totéž.
Do souboru index.py přidejte samostatnou funkci create_movie_id() s parametrem movies, která se podívá, jaké je nejvyšší ID v seznamu s filmy, a vrátí číslo o jedna větší. Mohla by se vám hodit tato vestavěná funkce.
def create_movie_id(movies):
ids = []
for movie in movies:
ids.append(movie['id'])
return max(ids) + 1
Nyní vše poskládáme dohromady:
class MovieListResource():
def on_get(self, request, response):
name = request.get_param('name')
base_url = request.prefix
filtered_movies = filter_movies(movies, name)
movies_repr = represent_movies(filtered_movies, base_url)
response.body = json.dumps(movies_repr)
def on_post(self, request, response):
movie = json.load(request.bounded_stream)
movie['id'] = create_movie_id(movies)
movies.append(movie)
Hotovo! Teď si můžeme vyzkoušet přidání nového filmu.
Varování
Mezi následujícími požadavky nesmíte restartovat aplikaci (Waitress musí po celou dobu běžet), jinak nebudou fungovat správně.
Naše API by nám mělo odpovědět s kódem 200 OK a bez těla:
$ curl -i "http://0.0.0.0:8080/movies" --request POST --header "Content-Type: application/json" --data '{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/"}'
HTTP/1.1 200 OK
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 15:18:44 GMT
Server: waitress
$ curl -i "http://MY-COMPUTER:8080/movies" --request POST --header "Content-Type: application/json" --data "{\"name\": \"New Kids Turbo\", \"name_cs\": \"New Kids Turbo\", \"year\": 2010, \"imdb_url\": \"https://www.imdb.com/title/tt1648112/\", \"csfd_url\": \"https://www.csfd.cz/film/295395-new-kids-turbo/\"}"
HTTP/1.1 200 OK
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 15:18:44 GMT
Server: waitress
Poznámka
JSON se musí psát vždy s dvojitými uvozovkami. Na Linuxu nebo macOS to není problém, protože v příkazové řádce fungují na ohraničení i jednoduché uvozovky a lze udělat následující:
--data '{"message": "Ahoj"}'
Na Windows bohužel nelze jednoduché uvozovky použít, k dispozici jsou pouze dvojité a ty kolidují s těmi v JSONu. Proto musíme v celém JSONu přepsat uvozovky na \":
--data "{\"message\": \"Ahoj\"}"
Další nepříjemností je skutečnost, že kvůli specifickému kódování textu v příkazové řádce na Windows není jednoduché posílat data, která budou obsahovat diakritiku. Následující tedy nebude fungovat:
--data "{\"message\": \"Čauky mňauky\"}"
V tomto návodu přidáme před uvozovky lomítka a diakritice se vyhneme. V praxi se dají oba problémy řešit tím, že data nebudeme psát přímo do příkazové řádky, ale uložíme si je vedle do souboru a řekneme programu curl, aby je z něj načetl:
--data @new-movie.json
Když se podíváme na seznam filmů, na konci odpovědi vidíme, že nový film dostal ID číslo 5 a jeho adresa je tedy http://0.0.0.0:8080/movies/5:
$ curl -i "http://0.0.0.0:8080/movies"
HTTP/1.1 200 OK
Content-Length: 363
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 15:30:27 GMT
Server: waitress
[{"name": "The Last Boy Scout", "url": "http://0.0.0.0:8080/movies/1"}, {"name": "Mies vailla menneisyytt\u00e4", "url": "http://0.0.0.0:8080/movies/2"}, {"name": "Sharknado", "url": "http://0.0.0.0:8080/movies/3"}, {"name": "Mega Shark vs. Giant Octopus", "url": "http://0.0.0.0:8080/movies/4"}, {"name": "New Kids Turbo", "url": "http://0.0.0.0:8080/movies/5"}]
Když se podíváme na adresu filmu, měli bychom dostat všechny informace o filmu:
$ curl -i "http://0.0.0.0:8080/movies/5"
HTTP/1.1 200 OK
Content-Length: 224
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 15:03:29 GMT
Server: waitress
{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/", "url": "http://0.0.0.0:8080/movies/5"}
Rada
Na kód celého programu se můžete podívat zde: server/12_post/index.py
Ukládání natrvalo¶
Možná jste si při svých pokusech všimli, že pokaždé, když restartujete aplikaci, vrátí se filmy do původního stavu. Je to proto, že stav našeho API udržujeme v Pythonu, v globálním seznamu. Ten se ukládá pouze v paměti počítače a když program skončí, odejde slovník do věčných lovišť.
Aby změny přežily restartování programu, museli bychom stav ukládat do souboru nebo do opravdové databáze. To je ovšem nad rámec těchto materiálů.
201 Created¶
Naše přidávání nyní sice funguje, ale nechová se úplně prakticky. Kdyby uživatel našeho API chtěl zjistit jakou dostal nově přidaný film adresu, musel by udělat několik dalších požadavků. Bylo by asi lepší, kdybychom v odpovědi na POST rovnou poslali informace o právě vytvořeném filmu.
Když se něco přidává, má se podle HTTP specifikace správně vracet status kód 201 Created. Stačí nám ale prostě vrátit tento kód, nebo je v tom i něco víc? Kdy přesně se tento kód používá?
Mohli bychom si o něm přečíst přímo ve standardu, RFC 7231, ale tam hrozí, že bude popis tak detailní, že mu začátečník snadno neporozumí. Skvělý přepis standardů kolem HTTP lze ale najít na MDN web docs:
The HTTP 201 Created success status response code indicates that the request has succeeded and has led to the creation of a resource … The common use case of this status code is as the result of a POST request.
Přesně v této situaci jsme. Výborně, toto se nás rozhodně týká.
The new resource is effectively created before this response is sent back and the new resource is returned in the body of the message, …
MDN nám radí, že v těle odpovědi bychom spolu s 201 Created měli poslat reprezentaci toho, co jsme zrovna vytvořili, tedy v našem případě nového filmu.
… its location being either the URL of the request, or the content of the Location header.
Toto znamená, že bychom ideálně ještě měli přidat do odpovědi hlavičku Location, jejíž hodnotou bude odkaz na vytvořený film. Druhá možnost je, že přímo adresa, kam se dělá požadavek, je adresou nově vytvořeného filmu, ale to není náš případ. Celé by to tedy mělo vypadat asi nějak takto:
$ curl -i "http://api.example.com/movies" --request POST --header "Content-Type: application/json" --data '{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/"}'
HTTP/1.1 201 Created
Content-Type: application/json
Location: http://api.example.com/movies/42
{
"url": "http://api.example.com/movies/42",
"name": "New Kids Turbo",
"name_cs": "New Kids Turbo",
"year": 1992,
"imdb_url": "https://www.imdb.com/title/tt1648112/",
"csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/"
}
Poznámka
Nebojte se dívat přímo do standardů nebo do jejich kvalitního přepisu, jako je na MDN. Ze začátku to může být tuhé čtení, ale dlouhodobě se to vyplácí. V některých případech není nejlepší se spoléhat na náhodné informace, které lze najít na internetu, jelikož mohou být zatíženy různými nepřesnostmi nebo mýty.
Zpět od čtení k programování. Změníme status kód a přidáme hlavičku. Po tom, co vložíme film do naší „databáze“, si uděláme jeho reprezentaci s url místo id a následně ji nastavíme jako tělo odpovědi:
class MovieListResource():
def on_get(self, request, response):
name = request.get_param('name')
base_url = request.prefix
filtered_movies = filter_movies(movies, name)
movies_repr = represent_movies(filtered_movies, base_url)
response.body = json.dumps(movies_repr)
def on_post(self, request, response):
movie = json.load(request.bounded_stream)
movie['id'] = create_movie_id(movies)
movies.append(movie)
movie_url = '{0}/movies/{1}'.format(request.prefix, movie['id'])
movie_repr = dict(movie)
movie_repr['url'] = movie_url
del movie_repr['id']
response.status = '201 Created'
response.set_header('Location', movie_url)
response.body = json.dumps(movie_repr)
Když nyní restartujeme Waitress a zkusíme opět přidat nový film, měli bychom dostat 201 Created s Location hlavičkou a tělem, v němž jsou všechny detaily. Díky url máme adresu na nový film nejen v hlavičce, ale i přímo v těle zprávy.
$ curl -i "http://0.0.0.0:8080/movies" --request POST --header "Content-Type: application/json" --data '{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/"}'
HTTP/1.1 201 Created
Content-Length: 224
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 16:30:48 GMT
Location: http://0.0.0.0:8080/movies/5
Server: waitress
{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/", "url": "http://0.0.0.0:8080/movies/5"}
$ curl -i "http://MY-COMPUTER:8080/movies" --request POST --header "Content-Type: application/json" --data "{\"name\": \"New Kids Turbo\", \"name_cs\": \"New Kids Turbo\", \"year\": 2010, \"imdb_url\": \"https://www.imdb.com/title/tt1648112/\", \"csfd_url\": \"https://www.csfd.cz/film/295395-new-kids-turbo/\"}"
HTTP/1.1 201 Created
Content-Length: 224
Content-Type: application/json; charset=UTF-8
Date: Wed, 01 May 2019 16:30:48 GMT
Location: http://MY-COMPUTER:8080/movies/5
Server: waitress
{"name": "New Kids Turbo", "name_cs": "New Kids Turbo", "year": 2010, "imdb_url": "https://www.imdb.com/title/tt1648112/", "csfd_url": "https://www.csfd.cz/film/295395-new-kids-turbo/", "url": "http://0.0.0.0:8080/movies/5"}
Poznámka
JSON se musí psát vždy s dvojitými uvozovkami. Na Linuxu nebo macOS to není problém, protože v příkazové řádce fungují na ohraničení i jednoduché uvozovky a lze udělat následující:
--data '{"message": "Ahoj"}'
Na Windows bohužel nelze jednoduché uvozovky použít, k dispozici jsou pouze dvojité a ty kolidují s těmi v JSONu. Proto musíme v celém JSONu přepsat uvozovky na \":
--data "{\"message\": \"Ahoj\"}"
Další nepříjemností je skutečnost, že kvůli specifickému kódování textu v příkazové řádce na Windows není jednoduché posílat data, která budou obsahovat diakritiku. Následující tedy nebude fungovat:
--data "{\"message\": \"Čauky mňauky\"}"
V tomto návodu přidáme před uvozovky lomítka a diakritice se vyhneme. V praxi se dají oba problémy řešit tím, že data nebudeme psát přímo do příkazové řádky, ale uložíme si je vedle do souboru a řekneme programu curl, aby je z něj načetl:
--data @new-movie.json
V hlavičce i v url rovnou vidíme, že nový film dostal ID číslo 5 a jeho adresa je tedy http://0.0.0.0:8080/movies/5.
Rada
Na kód celého programu se můžete podívat zde: server/13_created/index.py
Poznámka
Kód by šlo zjednodušit. Vytváření adresy filmu už máme na několika místech, mohlo by tedy mít svou funkci:
def get_movie_url(movie, base_url):
return '{0}/movies/{1}'.format(base_url, movie['id'])
Řádky, které vytvářejí reprezentaci filmu jsou téměř totožné s těmi, jež se nacházejí v MovieDetailResource. Mohli bychom vytvořit funkci represent_movie(), kterou by oba endpointy mohly využívat a díky ní bychom mohli oba o několik řádků zkrátit.
def represent_movie(movie, movie_url):
movie_repr = dict(movie)
movie_repr['url'] = movie_url
del movie_repr['id']
return json.dumps(movie_repr)
Takto bychom on_post() zkrátili na toto:
def on_post(self, request, response):
movie = json.load(request.bounded_stream)
movie['id'] = create_movie_id(movies)
movies.append(movie)
movie_url = get_movie_url(movie, request.prefix)
response.status = '201 Created'
response.set_header('Location', movie_url)
response.body = represent_movie(movie, movie_url)
Podobným úpravám se v programování říká refactoring. Jedná se o změny, které nemají žádný vliv na funkčnost z hlediska uživatele, ale vylepšují kód po stránce čitelnosti a udržovatelnosti. Smyslem tohoto návodu je ale především učit API, takže refactoring kódu bude spíše opomíjet.
Validace vstupních dat¶
Když uživatel našeho API přidává nový film, přiřazujeme mu ID a podle něj i URL. Nechceme tedy, aby měl uživatel možnost nám poslat film, který už nějaké ID nebo URL má. Bylo by dobré v takovém případě vrátit uživateli API chybu.
A co když pošle čísla místo řetězců? Co když budou nějaké položky úplně chybět? Co když je chceme mít nepovinné? Co když uživatel schválně nebo omylem pošle něco, co ani nelze přečíst jako JSON?
Naše API nyní v takových případech film v pořádku přijme, i když by nemělo. V případě, že nepošleme JSON, vrátí 500 Internal Server Error, což znamená, že naše API zcela selhalo a „spadlo“. Správně by taková situace neměla nastávat. Znamená to, že jsme s něčím nepočítali, neošetřili to, a chyba je na naší straně, tedy na straně tvůrců API. Uživatel s ní nic nenadělá. Je to ekvivalent toho, když náš program v Pythonu skončí vyjímkou.
V těchto materiálech se kontrolou vstupních dat zabývat nebudeme, ale je dobré vědět, že se tomu obecně říká validace a že pro JSON to řeší JSON Schema. V případě, že problém ošetříme a zjistíme, co dělá uživatel špatně, můžeme mu vrátit chybu 400 Bad Request. Nejlépe s co nejpodrobnějším vysvětlením v těle odpovědi (třeba ve formátu problem+json), aby mohl napravit omyly a poslat svůj požadavek správně.
Mažeme filmy¶
Pokud bychom chtěli umožnit filmy ze seznamu mazat, můžeme k tomu použít metodu DELETE. Ta funguje tak, že pokud ji klient pošle na nějakou adresu, je to instrukce pro API server, že má věc, kterou ta adresa reprezentuje, smazat. Zatímco přidávání se dělo do seznamu, a tedy na adrese /movies, mazání se týká jednoho konkrétního filmu, a proto bude na adrese /movies/3 (např.).
Jenže co vrátit za odpověď? Pokud něco smažeme a ono už to neexistuje, asi to nebudeme chtít vracet v těle odpovědi. Pokud nemáme co do těla odpovědi dát, můžeme v HTTP použít tzv. prázdnou odpověď. Má kód 204 No Content a dává klientovi najevo, že nemá v odpovědi už očekávat žádné tělo. Ostatně, doporučuje nám ji pro metodu DELETE i MDN.
$ curl -i "http://api.example.com/movies/3" --request DELETE
HTTP/1.1 204 No Content
Pojďme si mazání naprogramovat. Začneme opět pomocnou funkcí, která bude hledat film podle jeho ID a pokud jej najde, z naší „databáze“ jej smaže.
Do souboru index.py přidejte samostatnou funkci remove_movie_by_id() s parametry movies a id, která podle ID najde film a smaže jej ze seznamu. Funkce bude vracet True nebo False podle toho, jestli se jí povedlo film najít nebo ne.
def remove_movie_by_id(movies, id):
for i, movie in enumerate(movies):
if movie['id'] == id:
del movies[i]
return True
return False
Informace o tom, jestli film v seznamu byl nebo ne se nám bude hodit. Opět bychom totiž měli pamatovat na to, že klient může poslat požadavek na smazání filmu s ID číslo 42, ačkoli žádný takový neexistuje. Asi by se moc nestalo, kdybychom odpověděli, že se neexistující film povedlo smazat, ale bude lepší, když druhou stranu informujeme o tom, že se pokouší dělat něco, co nejde.
class MovieDetailResource():
def on_get(self, request, response, id):
movie = get_movie_by_id(movies, id)
if movie is None:
response.status = '404 Not Found'
else:
base_url = request.prefix
movie_repr = dict(movie)
movie_repr['url'] = '{0}/movies/{1}'.format(base_url, movie['id'])
del movie_repr['id']
response.body = json.dumps(movie_repr)
def on_delete(self, request, response, id):
removed = remove_movie_by_id(movies, id)
if removed:
response.status = '204 No Content'
else:
response.status = '404 Not Found'
Když se podíváme na Žralokonádo a budeme ho chtít smazat ze seznamu, měli bychom dostat prázdnou odpověď s kódem 204 No Content.
$ curl -i "http://0.0.0.0:8080/movies/3" --request DELETE
HTTP/1.1 204 No Content
Connection: close
Date: Thu, 02 May 2019 20:58:43 GMT
Server: waitress
Jestliže to zkusíme znovu, měli bychom dostat chybu, protože film s ID číslo 3 už nebude existovat. Stejně tak dostaneme chybu, pokud zkusíme nějaké nesmyslné ID:
$ curl -i "http://0.0.0.0:8080/movies/42" --request DELETE
HTTP/1.1 404 Not Found
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Thu, 02 May 2019 21:02:03 GMT
Server: waitress
Rada
Na kód celého programu se můžete podívat zde: server/14_delete/index.py
Zabezpečujeme¶
Už od osmdesátých let víme, že Bruce Willis se jen tak smazat nenechá. Pojďme tuto nezpochybnitelnou pravdu odrazit v našem API. Pokud se někdo pokusí odebrat ze seznamu film s Brucem v hlavní roli, bude mu tento požadavek odepřen. Abychom to mohli udělat, potřebujeme pro každý film údaje o hercích v hlavních rolích:
movies = [
{
'id': 1,
'name': 'The Last Boy Scout',
'name_cs': 'Poslední skaut',
'year': 1991,
'stars': ['Bruce Willis', 'Damon Wayans', 'Chelsea Field'],
'imdb_url': 'https://www.imdb.com/title/tt0102266/',
'csfd_url': 'https://www.csfd.cz/film/8283-posledni-skaut/',
},
{
'id': 2,
'name': 'Mies vailla menneisyyttä',
'name_cs': 'Muž bez minulosti',
'year': 2002,
'stars': ['Markku Peltola', 'Kati Outinen', 'Juhani Niemelä'],
'imdb_url': 'https://www.imdb.com/title/tt0311519/',
'csfd_url': 'https://www.csfd.cz/film/35366-muz-bez-minulosti/',
},
{
'id': 3,
'name': 'Sharknado',
'name_cs': 'Žralokonádo',
'year': 2013,
'stars': ['Ian Ziering', 'Tara Reid', 'John Heard'],
'imdb_url': 'https://www.imdb.com/title/tt2724064/',
'csfd_url': 'https://www.csfd.cz/film/343017-zralokonado/',
},
{
'id': 4,
'name': 'Mega Shark vs. Giant Octopus',
'name_cs': 'Megažralok vs. obří chobotnice',
'year': 2009,
'stars': ['Debbie Gibson', 'Lorenzo Lamas', 'Vic Chao'],
'imdb_url': 'https://www.imdb.com/title/tt1350498/',
'csfd_url': 'https://www.csfd.cz/film/258268-megazralok-vs-obri-chobotnice/',
},
]
Nyní můžeme vrátit chybu 403 Forbidden, pokud klient se svým požadavkem narazí na Bruce:
class MovieDetailResource():
def on_get(self, request, response, id):
movie = get_movie_by_id(movies, id)
if movie is None:
response.status = '404 Not Found'
else:
base_url = request.prefix
movie_repr = dict(movie)
movie_repr['url'] = '{0}/movies/{1}'.format(base_url, movie['id'])
del movie_repr['id']
response.body = json.dumps(movie_repr)
def on_delete(self, request, response, id):
movie = get_movie_by_id(movies, id)
if movie is None:
response.status = '404 Not Found'
elif 'Bruce Willis' in movie['stars']:
response.status = '403 Forbidden'
else:
remove_movie_by_id(movies, id)
response.status = '204 No Content'
Nejdříve využijeme funkce get_movie_by_id(), která nám vrátí film podle ID. Pokud jej nenajde, rovnou skončíme s chybou 404 Not Found. Potom se podíváme, jestli ve filmu hraje Bruce. Pokud ano, skončíme s chybou 403 Forbidden. Jinak použijeme funkci remove_movie_by_id() pro smazání filmu a vracíme 204 No Content. Návratovou hodnotu remove_movie_by_id() nyní již nepotřebujeme, protože v této fázi již víme, že film určitě existuje.
$ curl -i "http://0.0.0.0:8080/movies/1" --request DELETE
HTTP/1.1 403 Forbidden
Content-Length: 0
Content-Type: application/json; charset=UTF-8
Date: Thu, 02 May 2019 21:57:45 GMT
Server: waitress
Poznámka
Není úplně zřejmé, proč je přístup zamezen. Zatímco u chyby 404 Not Found je to jasné z definice, u 403 Forbidden by bylo dobré poslat nějaký důvod:
response.status = '403 Forbidden'
response.body = json.dumps({'message': "Bruce Willis dies hard"})
Samozřejmě by opět bylo lepší pro formát těla využít nějaký standard, například již zmíněný problem+json.
Podobným způsobem bylo zabezpečeno API od OMDb. Dokud jsme neudělali požadavek s API klíčem, nedostali jsme jinou odpověď než chybu:
$ curl -i "https://www.omdbapi.com/?t=westworld"
HTTP/2 401
...
{"Response":"False","Error":"No API key provided."}
Jediným rozdílem je to, že v jejich API byl použit kód 401 Unauthorized. Ten se má poslat ve chvíli, kdy má klient šanci oprávnění získat a požadavek provést znovu. V případě OMDb bylo potřeba se zaregistrovat, obdržet API klíč a poslat ho jako parametr. V našem případě oprávnění nijak dostat nelze. Abychom mohli vracet 401 Unauthorized, museli bychom doprogramovat nějaký způsob, jak Bruce přelstít.
Rada
Na kód celého programu se můžete podívat zde: server/15_forbidden/index.py
Uveřejňujeme API¶
Pokaždé, když jsme spustili Waitress, mohli jsme své API zkoušet na adrese http://0.0.0.0:8080. Možná jste si všimli, že když Waitress v příkazové řádce nejela, adresu nešlo použít.
$ curl -i http://0.0.0.0:8080/
curl: (7) Failed to connect to 0.0.0.0 port 8080: Connection refused
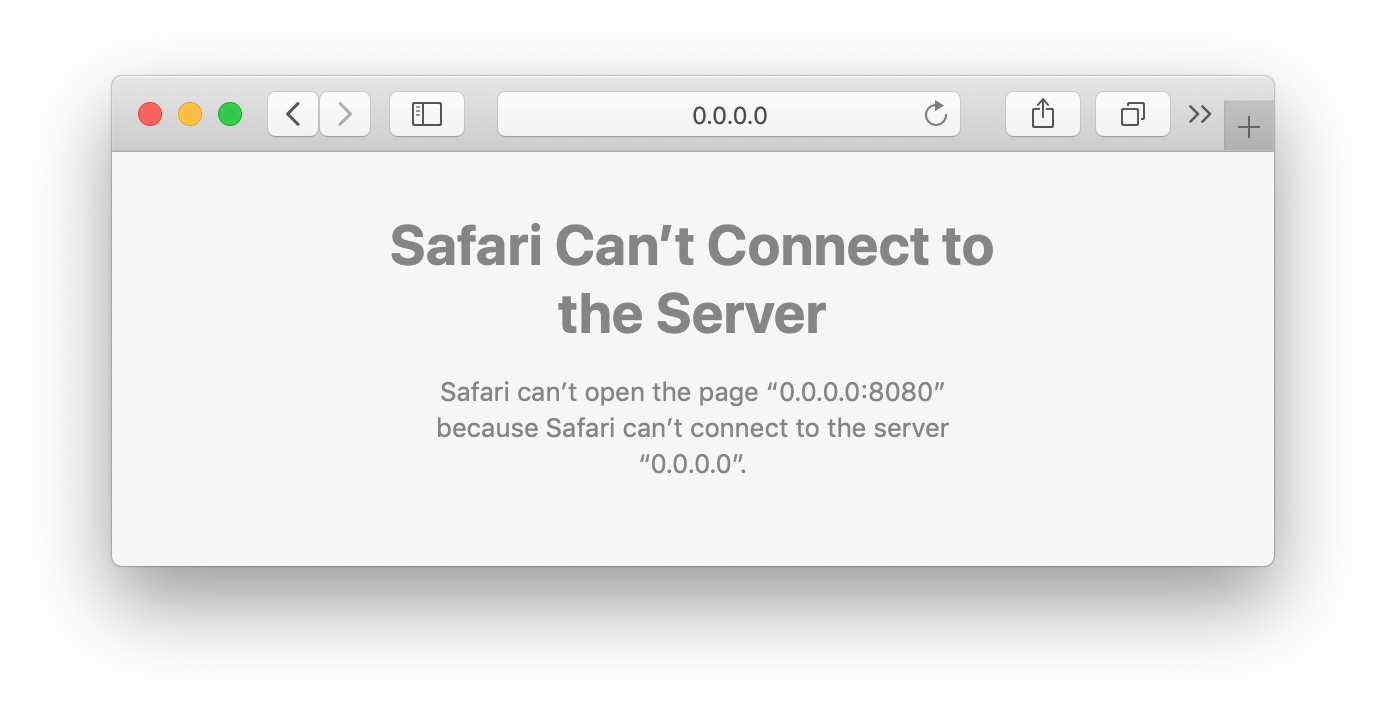
Tato adresa je totiž spjata s tím, jestli Waitress zrovna jede nebo ne. Také tato adresa funguje jen pro nás. I když spustíme Waitress a na adrese http://0.0.0.0:8080 uvidíme naše API, nikdo jiný jej na té samé adrese nenajde. Je to proto, že adresa 0.0.0.0 znamená „na tomto počítači“. Pokud bychom tedy někomu poslali http://0.0.0.0:8080/movies jako odkaz na seznam našich oblíbených filmů, je to podobné, jako bychom posílali C:\\Users\Honza\Documents\filmy.xlsx.
Poznámka
Adres, které znamenají „na tomto počítači“ je více. Ekvivalentně k http://0.0.0.0:8080 funguje i http://127.0.0.1:8080 nebo http://localhost:8080. Používáte-li Windows, vypíše vám Waitress dokonce úplně jinou adresu, která bude obsahovat název vašeho počítače v síti. Můžete si vyzkoušet, které z uvedených adres vám budou fungovat, když zapnete Waitress.
Now¶
Abychom mohli naše API někomu ukázat, musíme jej nejdříve uveřejnit na internet. Můžeme k tomu využít službu Now od společnosti ZEIT. Ta dokáže vzít náš adresář s aplikací a přenést jej na internet. Naše aplikace dostane přidělenou adresu, například https://cojeapi.honzajavorek.now.sh, a na té ji bude moci používat kdokoliv na světě, 24 hodin denně.
Příprava¶
V témže adresáři, ve kterém máme
index.py, vytvoříme nový soubornow.jsons následujícím obsahem:{ "version": 2, "builds": [ { "src": "index.py", "use": "@now/python", "config": { "maxLambdaSize": "10mb" } } ], "routes": [ { "src": "/(.*)", "dest": "index.py" } ] }
Je to konfigurační soubor pro službu Now, který jí říká, jak má s naším projektem pracovat.
V témže adresáři, ve kterém máme
index.py, vytvoříme nový souborrequirements.txts následujícím obsahem:falcon
Tím říkáme, že aby naše API fungovalo, bude potřeba nejdříve nainstalovat Falcon. Waitress do souboru psát nebudeme. Potřebujeme ji jen pro spuštění na našem počítači, now.sh si poradí i bez ní.
Aby Now správně fungovalo, nesmíme mít v adresáři nic jiného, než naši aplikaci a soubory, které jsme právě vytvořili.
Pokud se v našem adresáři nachází cokoliv jiného (podadresáře nebo soubory), než
index.py,now.jsonarequirements.txt, musíme se toho nějak zbavit, jinak by se to Now snažilo nahrát na internet. Řekněme, že obsah našeho adresáře vypadá například takto:venv index.py index-pokus1.py index-pokus2.py curl.exe now.json requirements.txt
Máme tam navíc program curl, nějaké předešlé pokusy v souborech
index-pokus1.pyaindex-pokus2.py, a virtuální prostředí v adresářivenv. Pokusy i curl přemístíme na jiné místo v počítači. Obsah našeho adresáře bude nyní takovýto:venv index.py now.json requirements.txt
Zbývá podadresář
venvs virtuálním prostředím, který bude Now překážet, ale my bychom jej rádi zachovali. Naštěstí existuje způsob, jak Now říct, že má něco ignorovat. Vytvoříme soubor.nowignore(ano, název souboru začíná tečkou) a do něj napíšeme, co máme v adresáři navíc:venv
Nyní bude Now vědět, že má na internet nahrát vše v našem adresáři kromě
venv.Poznámka
Pokud materiály procházíte v rámci workshopu a tato část vám přijde matoucí, nebojte se poradit s kouči.
Instalace Now¶
Varování
Pokud materiály procházíte v rámci workshopu a program now jste si už nainstalovali v rámci přípravy, můžete tuto sekci přeskočit.
Nejdříve ověříme, zda náhodou už nemáme nainstalovaný program now, kterým se služba Now ovládá. V příkazové řádce necháme program vypsat svou verzi, čímž ověříme, jestli funguje:
$ now --version
> UPDATE AVAILABLE Run `npm i -g now@latest` to install Now CLI 16.7.3
> Changelog: https://github.com/zeit/now/releases/tag/now@16.7.3
16.7.1
Vypíše-li se verze programu now, jak je na příkladu výše, máme hotovo. Na číslu verze nezáleží. Program now je funkční a instalaci můžeme přeskočit.
Pokud se místo verze vypíše něco v tom smyslu, že příkaz ani program now neexistuje, pak je potřeba jej doinstalovat.
Začneme instalací Node.js.
Poznámka
Proč instalace zahrnuje i jakýsi Node.js? Je to proto, že program now je napsán v jazyce JavaScript. Než jej tedy budeme moci nainstalovat a spustit, potřebujeme na náš počítač nejdříve doinstalovat JavaScript. Běžně se JavaScript spouští v internetovém prohlížeči, ale balík s názvem Node.js jej umožňuje používat k programování aplikací podobně jako se používá Python.
Instalujeme standardní cestou přes správce balíčků. V distribucích Debian nebo Ubuntu takto:
$ sudo apt-get install nodejs
V distribuci Fedora takto:
$ sudo dnf install nodejs
Balík Node.js nainstaluje i program s názvem npm (něco jako pip pro JavaScript), kterým už můžeme nainstalovat now:
$ npm install now@latest --global
Nakonec necháme program now vypsat svou verzi, čímž ověříme, jestli funguje:
$ now --version
Začneme instalací Node.js.
Poznámka
Proč instalace zahrnuje i jakýsi Node.js? Je to proto, že program now je napsán v jazyce JavaScript. Než jej tedy budeme moci nainstalovat a spustit, potřebujeme na náš počítač nejdříve doinstalovat JavaScript. Běžně se JavaScript spouští v internetovém prohlížeči, ale balík s názvem Node.js jej umožňuje používat k programování aplikací podobně jako se používá Python.
Na stránkách Node.js stáhneme „Windows Installer“ a spustíme. Nainstaluje se i program s názvem npm (něco jako pip pro JavaScript), kterým už můžeme nainstalovat now:
$ npm install now@latest --global
Nakonec necháme program now vypsat svou verzi, čímž ověříme, jestli funguje:
$ now --version
Pokud používáme Homebrew k instalaci programů, budeme mít práci o něco snazší. Začneme instalací Node.js.
Poznámka
Proč instalace zahrnuje i jakýsi Node.js? Je to proto, že program now je napsán v jazyce JavaScript. Než jej tedy budeme moci nainstalovat a spustit, potřebujeme na náš počítač nejdříve doinstalovat JavaScript. Běžně se JavaScript spouští v internetovém prohlížeči, ale balík s názvem Node.js jej umožňuje používat k programování aplikací podobně jako se používá Python.
Instalujeme standardní cestou:
$ brew install node
Balík Node.js nainstaluje i program s názvem npm (něco jako pip pro JavaScript), kterým už můžeme nainstalovat now:
$ npm install now@latest --global
Nakonec necháme program now vypsat svou verzi, čímž ověříme, jestli funguje:
$ now --version
Začneme instalací Node.js.
Poznámka
Proč instalace zahrnuje i jakýsi Node.js? Je to proto, že program now je napsán v jazyce JavaScript. Než jej tedy budeme moci nainstalovat a spustit, potřebujeme na náš počítač nejdříve doinstalovat JavaScript. Běžně se JavaScript spouští v internetovém prohlížeči, ale balík s názvem Node.js jej umožňuje používat k programování aplikací podobně jako se používá Python.
Na stránkách Node.js stáhneme „macOS Installer“ a spustíme. Nainstaluje se i program s názvem npm (něco jako pip pro JavaScript), kterým už můžeme nainstalovat now:
$ npm install now@latest --global
Nakonec necháme program now vypsat svou verzi, čímž ověříme, jestli funguje:
$ now --version
Nahráváme pomocí Now¶
Nyní zkusíme na příkazové řádce, v našem adresáři s aplikací, spustit příkaz pro přihlášení:
$ now login
Now po nás bude chtít e-mailovou adresu. Zadáme ji a ověříme v naší e-mailové schránce. Když nyní spustíme now, nahraje se naše aplikace na internet (bude to nejspíše chvíli trvat):
$ now
Poznámka
Pokud nahrávání skončí chybou, ujistíme se, že jsme ve správné složce a že máme správně soubor .nowignore.
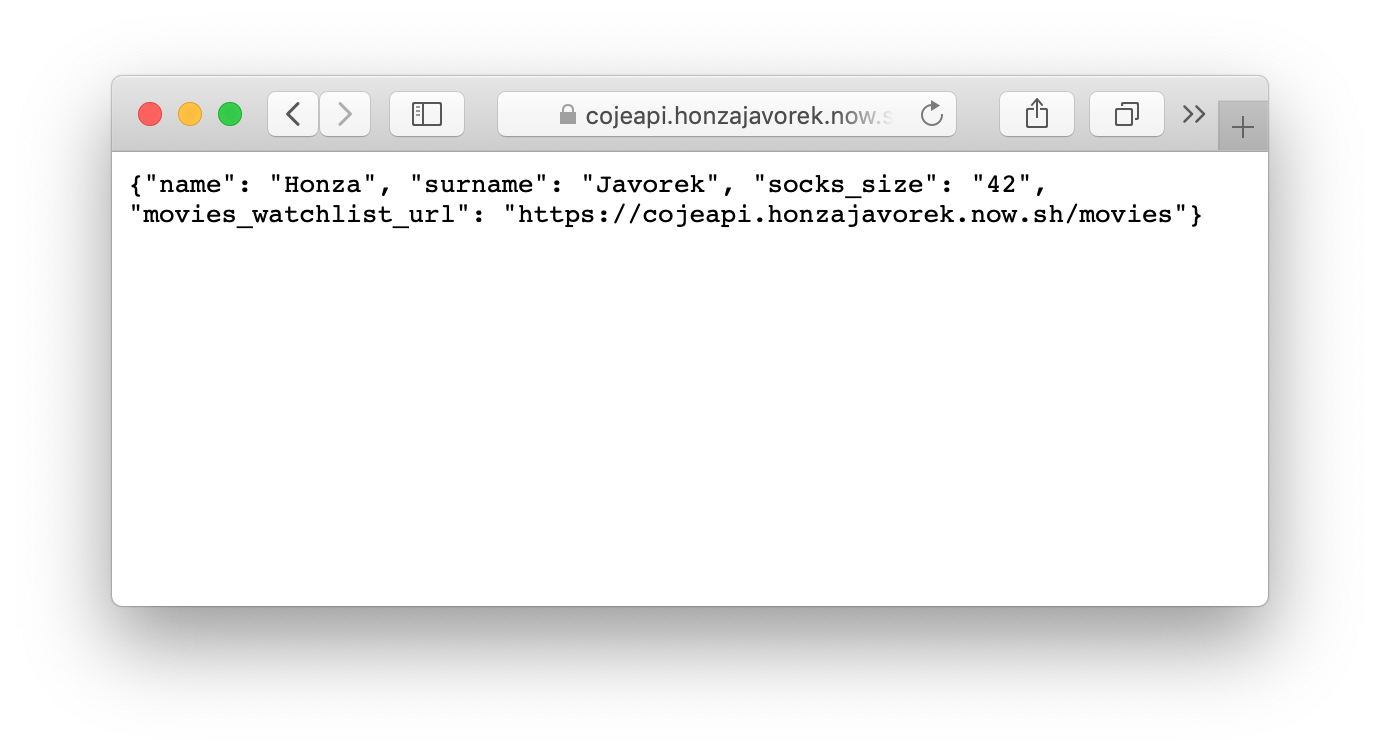
Po nějaké době bychom měli dostat adresu, na které můžeme naše API najít - něco ve tvaru https://cojeapi.honzajavorek.now.sh. Pokud na tuto adresu půjdeme v prohlížeči, měli bychom vidět naše API:
Samozřejmě můžeme na naše API posílat požadavky i pomocí curl:
$ curl -i "https://cojeapi.honzajavorek.now.sh"
HTTP/2 200
content-type: application/json
content-length: 129
...
server: now
{"name": "Honza", "surname": "Javorek", "socks_size": "42", "movies_watchlist_url": "https://cojeapi.honzajavorek.now.sh/movies"}
A co je ještě lepší, na rozdíl od všech předchozích případů, nyní může na naše API posílat požadavky i někdo jiný!
Pokud procházíte tento návod v rámci workshopu, například PyWorking, pošlete tuto adresu někomu jinému z účastníků, ať zkusí se svým prohlížečem a s curl posílat požadavky na vaše API. Vy zase můžete zkoušet jejich API. Zkuste do jejich seznamu přidat svůj oblíbený film, nebo film z jejich seznamu smazat.
Pozor na lomítka na konci adres - tak jak jsme naprogramovali naše API a nastavili jej na Now vyústí v citlivé dodržování rozdílu mezi
/movies- 200 OK/movies/- 404 Not Found
Aktualizujeme pomocí Now¶
Naše API má teď dva životy. Zaprvé existuje jako tzv. „vývojová verze“ (anglicky development, někdy dev environment, počeštěně dev prostředí), která se nachází pouze na našem počítači a kterou můžeme snadno změnit a poté spustit přes Waitress.
Zadruhé existuje jako tzv. „produkce“ (anglicky production, production environment, tedy produkční prostředí), kde k našemu API mohou přistupovat jeho uživatelé.
Když změníme zdrojový kód souborů na našem počítači, projeví se to ve vývojové verzi na adrese http://0.0.0.0:8080, ale už ne na https://cojeapi.honzajavorek.now.sh. Aby se to projevilo i tam, musíme říct Now, aby znovu nahrálo naše soubory a aktualizovalo produkci s tím, co zrovna máme na počítači:
$ now
Ano, pokud budeme chtít udělat v našem API změny a ty opět promítnout veřejně, stačí jen znova spustit příkaz now v téže složce, kde máme index.py, requirements.txt, now.json a .nowignore.
Dokumentujeme API¶
Jak se uživatel našeho API doví, co z API dostane? Status kódy a hlavičky jsou pevně dané protokolem HTTP, ale asi jste si všimli, že strukturu těl odpovědí jsme si v zásadě vymýšleli. Sice jsme je posílali jako JSON, ale to je obecný formát, který nic neříká o významu dat. Pokud by někdo psal program, který s naším API pracuje, bude muset nejdříve nějak zjistit, co má očekávat v odpovědích.
Už jsme zmiňovali, že pro chyby nějaké standardy existují. Pro zbytek odpovědí také (např. JSON:API nebo HAL). Pokud je použijeme, může tvůrce klienta dosáhnout nebeské nirvány:
Program se může sám v API zorientovat díky odkazům. Takto fungují jen nefalšovaná REST API. Pokud je API tímto způsobem „samonosné“, označuje se tato vlastnost jako HATEOS (nebo jen hypermedia, což je písmeno H z oné zkratky).
Nefalšovaných REST API je však velmi málo. Většinou si bohužel každý vymyslí odpovědi tak, jak se mu zrovna hodí, a s odkazy se nezatěžuje. Zbývají tedy dva způsoby:
Reverse engineering, tzn. metoda pokus a omyl. Tvůrce klienta strukturu API luští jako šifru. Zkouší posílat různé věci a podle toho, co dostává zpět, usuzuje jak API nejspíš funguje. Nevýhodou je, že je to pracné, zdlouhavé, a vede to k chybným předpokladům o API a tedy i mnoha chybám.
Čtení dokumentace. Tato varianta se jeví jako zřejmá, ale často se stane, že dokumentace se rozchází s realitou, je neúplná, nebo zcela chybí.
Jak vidíte, jako tvůrci serverové části API máme tedy velmi důležitý úkol. Musíme napsat dokumentaci, aby jej mohl někdo bez újmy na vlastním zdraví použít. Potom pokaždé, když v API něco změníme, bychom měli dokumentaci aktualizovat.
Formáty na dokumentaci API¶
Občas stačí, když napíšeme dokument, kde vysvětlíme, co se na jakém endpointu nachází. Podívejte se, jak je zdokumentováno například Yelp API, GitHub API, nebo Slack API. Snad nejlépe zdokumentované API vůbec je Stripe API.
Dokumentovat se dá klidně v Google Docs, ale většinou se spíše používá Markdown nebo jiný značkovací jazyk. Pokud je však API velké, je lepší si pomoci přímo nějakým formátem určeným k dokumentaci API. Nejpoužívanější jsou OpenAPI a API Blueprint. Například popis našeho API v druhém jmenovaném by mohl začínat následovně:
# Moje API
## GET /
Vypíše základní informace o mé osobě.
+ Response 200 (application/json)
+ Attributes
+ name: `Honza` (string) - Moje jméno
+ surname: `Javorek` (string) - Moje příjmení
+ socks_size: `42` (number) - Moje velikost ponožek
+ movies_watchlist_url (string) - Odkaz na seznam filmů, které chci vidět
Protože je API Blueprint založený na Markdownu, můžeme soubor uložit jako mojeapi.md a takto nám jej hezky zobrazí i GitHub. Pokud soubor nahrajeme do služby Apiary, vygeneruje nám z něj profesionální dokumentaci.
Poznámka
Pokud by vás dokumentování bavilo, mrkněte na stránky Write the Docs, kde je i návod, jak s dokumentováním začít. Kdyby vás dokumentování bavilo hodně, WTD každoročně v Praze organizují skvělou konferenci.
Frameworky pro tvorbu serveru¶
V tomto návodu jsme si ukázali, jak vyrobit jednoduché API s pomocí frameworku Falcon, jenž je pro toto použití vyladěný.
Jelikož jsou webová API založena na podobných principech jako webové stránky, šlo by použít i známější frameworky Flask nebo Django. Pokud bychom v nich ale tvořili složitější API, brzy by nám přišlo, že s takovým frameworkem spíše bojujeme, než aby nám pomáhal.
Např. chyby by takový framework standardně posílal jako HTML, přitom by bylo lepší, kdyby byly také naformátovány jako JSON. Museli bychom ručně doplnit kód, který upraví výchozí chování Flasku nebo Djanga a bude chyby posílat tak, jak se v JSON API sluší a patří.
Z tohoto a dalších důvodů je tedy výhodnější buďto pro API využít specializovaný framework, jakým je Falcon, nebo se poohlédnout po doplňcích do Flasku, popřípadě Djanga, které nám tvorbu API usnadní. To jsou např. Django REST Framework, Flask-Restful, Eve, a další.